The Features page in the Pipeline section is an exploratory page that visualizes the feature generation, transformation, and selection that occur during the Pipeline run.
You can get valuable insights by analyzing the types of features selected for given targets. This helps to better understand what influences predictive accuracy.
This page includes an Generalization, Transformers, and a Targets view. Click the buttons at the top of the page to switch between the views.
View Predictive Features
The Transformers view provides insights into the predictive features generated and selected during Pipeline across all targets. Metrics for how long feature engineering ran during the pipeline are also provided.
Feature Engineering Duration: The number of seconds feature engineering ran.
Feature Transformation Rounds: The number of rounds that occurred during feature engineering.
Max Feature Selection Rounds: The maximum number of rounds of feature selection run across all targets.
Total Unique Generated Features: The number of features generated or transformed by the XperiFlow engine.
Total Unique Selected Features: The number of features used by at least one model.
Feature Transformer Distribution Chart: A bar chart showing how many features were created using each type of transformer.
Feature Type Distribution: A bar chart showing the number of features for each data type.

The naming convention for features signals the order in which transformations to them occurred during Pipeline and can include the following terms:
CleanNegativeToZero: If you chose to not allow negative targets, all negative target values are cleaned by assigning them as zeros.
CleanMissing: This is a standard job by XperiFlow to impute for missing values.
From Source: Shows how many features and events are from the data source.
Lag(frequency=[X],lag_step=[Y]|): A feature like this is a lag of Y periods with X frequency.
TimeBreakdown-[X]: This feature analyzes the minute, hour, day, week, or month that a data point occurred.
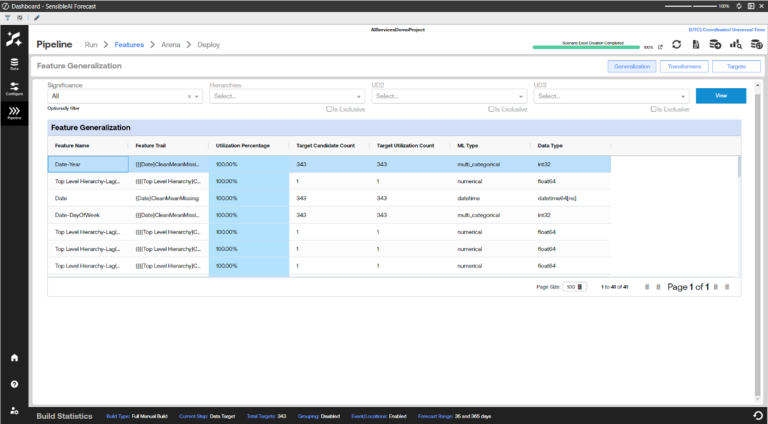
View Generalization Pipeline Features
The Generalization view provides insights into the how generalized different features were across targets. The data shown can be broken down by target dimension, significance, and which hierarchies to include. The grid shows the following information:
Feature Name: The shorter common feature name for features. For example, “SalesLunch-Lag7” and “SalesDinner-Lag7” would both be “Lag7” (assuming SalesLunch and SalesDinner are targets).
Feature Trail: The full common feature name for features. Similar to Feature Name, but the full name instead of the short name.
Utilization Percentage: The percentage of eligible targets that used the feature in at least one model.
Target Candidate Count: The number of targets that were eligible to use the feature.
Target Utilization Count: The number of targets that used the feature in at least one model.
Data Type: The data type of the given feature.
View Predictive Features for Targets
The Targets view provides insights into the different predictive features that were selected for each given target and used by models during Pipeline.
Click a target in the Targets pane to see how many features were selected for it and used by models during the pipeline run and how many of those selected features are in each feature category. The table lists each selected feature for the current target, with its type and name, and whether the feature is an event feature, time-related feature, or if it originated from source data.
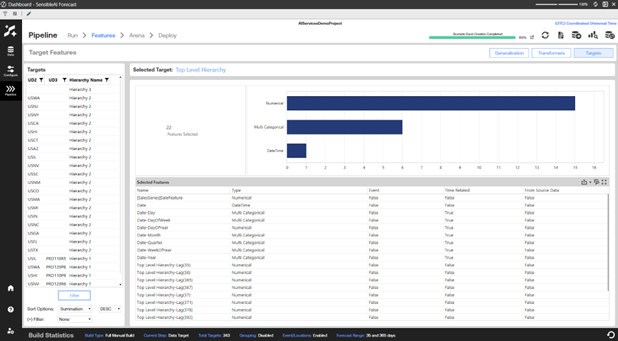
Selected features are broken down by types and represented visually on this page. Types include:
Numerical: Examples of this include temperature (67 degrees) or a 7-day lagged value (a feature for avocado sales today is the avocado sales from 7 days ago).
Multi Categorical: An example of this would be day of the week (1-7).
DateTime: The date dimension is always included in this.
Binary Categorical For example: “For the given date (row of data), did the event St. Patrick’s Day occur (0 or 1)?”




