Data Collection Process
Having a good understanding of how your data is collected is extremely important. The quality of the data collection process determines the amount of effort needed to pre-process data prior to using Sensible Machine Learning.
The following sections describe what defines a good source data collection process.
Uniform Data Collection
Uniform Data Collection is defined as having a consistent data collection procedure for building the source data set.
Important questions to consider are:
-
Is there a consistent data collection procedure across all business units or do business units implement their own practices?
-
Do all business units report the same information, on the same frequency, and at the same time?
Ensuring that data is sourced using the same procedure and practices across all sources minimizes the effort to identify and correct any discovered inconsistencies. Overall, a highly fragmented and disjointed data collection process should be addressed and fixed before using a data source in Sensible Machine Learning.
Uniform Intra-Target Collection
Uniform intra-target collection is defined as a particular target maintaining the same data collection practices and procedures over time. Important questions to consider are:
-
Does the frequency and the collection lag of the target remain consistent over time?
-
Do the number of sources feeding a target remain consistent over the course of time?
Intra-target collection process integrity is important to maintain over the course of time. Otherwise, you risk the statistical and ML models mistaking a data collection inconsistency for changes in the underlying data pattern for that target.
The following example illustrates the difference between a non-uniform intra-target collection procedure versus a uniform procedure.
A clothing company that owns a variety of clothing brands wants to predict the unit sales of shirts and pants. They have historical retail sales data dating back to 2014. In 2017, this clothing company merged Brand B that they own with Brand A (having Brand B be absorbed by Brand A).
Consolidate Data at Merger (Non-Uniform)
The following table shows a non-uniform intra-target collection pattern. It is non-uniform because from 01/01/2017 onward there are two sources feeding BrandA-Shirts and BrandA-Pants. Before 01/01/2017 there was only one source. This fundamentally changes the collection process for these targets.
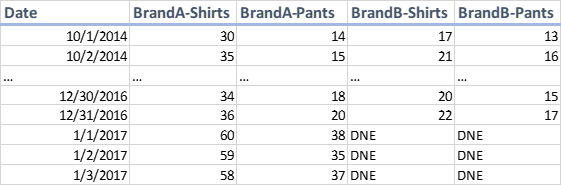
The problem with this method is that the models that run against BrandA-Shirts and BrandA-Pants are not aware that this merger happened. The models assume that BrandA targets magically and organically doubled their sales at the start of the year. In future projections, the models may see this doubling as a common occurrence and predict this to happen at the start of every year which would be wrong.
The Correct Way: Backdate the Consolidation of Brands to the Beginning of the Data (Uniform)
This is the correct way to handle this merger from a machine learning data perspective because it maintains uniformity of target data collection over time. With the uniform option, even though the merger officially occurred on 01/01/2017, the values of Brand A and Brand B are aggregated back to the beginning of the data set.
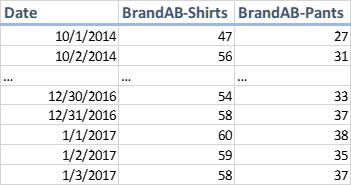
This has two benefits over a non-uniform intra-target collection.
-
The models are trained off the combined Brand A and B which is the case moving forward.
-
This removes the Shutdown Brand B from the data set that serves no purpose moving forward and should not be receiving predictions.