The Deploy page provides information that lets you fully analyze and understand the effectiveness of your model before deploying it to production. Once satisfied, you deploy your model using this page, which collects necessary information from the pipeline job to be able to run the deployed models in utilization. This information includes:
-
The most optimal hyperparameters for deployed models.
-
How to generate and transform features selected for the deployed models.
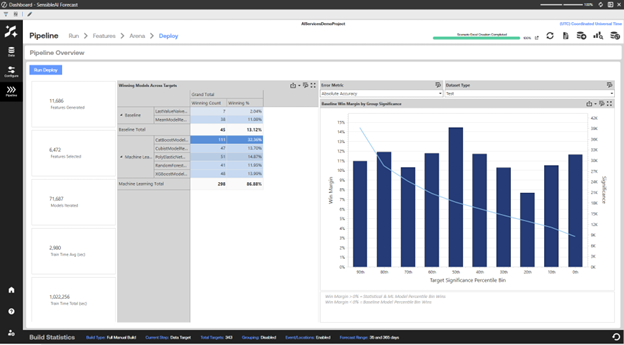
Analyze Pipeline Performance Overview Statistics
General statistics shown here include:
Features Generated: Number of features generated for the entire data set.
Features Selected: Number of features selected for the data set based on being able to positively contribute to predictive accuracy.
Models Iterated: Number of times models were iterated with different hyperparameter settings during the pipeline job.
Train Time: Total train time across all targets and target groups during Pipeline. This total time is not sequential however, as much of the Pipeline is run in parallel through the XperiFlow Conduit Orchestration.
The charts on this page include:
“Best” Models: Descending bar chart that visualizes the breakdown of best models selected across all targets, so you can understand how frequently different models and model types are winning.
Baseline Win Margin by Group Significance: Each bar in this chart represents an even-sized bin of targets. Bar heights indicate the percent by which the best statistical or machine learning model beat or lost to the best baseline model based on the selected error metric, summed across all targets within the bin.
The light blue line in the chart represents the bin's total significance. Bin refers to the value amount selected during the Data section, such as total units or dollars. Positive win margins are ideal. This means that machine learning and statistical models are beating the simplistic models on average.
It is possible however, for a bar to be negative due to an instance where the best baseline model beats the best machine learning or statistical model. For example, in a ten-target bin, nine machine learning and statistical models can beat the best baseline by 10 percent each, but one baseline model that wins by 120 percent can swing the bar to be negative.
Use the Overview view to get valuable insight by analyzing the Best Models and Baseline Win Margin by Group Significance charts. This can help answer questions such as:
-
How often are my machine learning and statistical models beating the best baseline model?
-
By how much are my best machine learning and statistical models beating the best baseline model?
-
Are the best baseline models being beaten for my most significant targets? This is specific to non-units-based value dimensions, such as sales dollars.
Deploy Your Model
After reviewing the available statistics and visualizations for each target, click the Run Deploy button. This creates the deployment job, which upon completion changes the project's status and moves the project from the Model Build phase to the Utilization phase.
The deployment job takes the best models selected during pipeline and deploys them for generating forecasts.
Additionally, after the models have been chosen for deployment, SensibleAI Forecast creates the feature schemas and pre-trained models needed to run predictions against the models in the Utilization phase.
 Introducing SensibleAI Forecast
Introducing SensibleAI Forecast

